
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- was
- 테크블로그
- deploy
- MongoDB
- projection
- 톰캣
- 확인
- aggregation
- Pipeline
- 무중단
- slowQuery
- kill
- web
- troubleshooting
- 상태
- GRACEFUL
- 진행
- httpd
- longQuery
- no space left
- maven
- apache
- NoSQL
- restart
- 인덱스
- LocalRepository
- 배포
- 성능
- 몽고DB
- tomcat
- Today
- Total
목록전체 글 (9)
boogie의 가벼운 개발 일기
 [Feedly] RSS 피드로 개발 트렌드를 구독하자
[Feedly] RSS 피드로 개발 트렌드를 구독하자
후배님들과 이야기를 하다보면 어떻게 이렇게 최신 트렌드들을 자연스럽게 접하고 있을까 궁금할때가 있다. 대체로 (컴퓨터 공학과 출신의 경우)학교 동기나 (신입사원들의 경우)회사 동기들과 자주 새로나온 기술등에 대해 이야기를 나누는데서 많은 정보를 얻는 듯 하다. 내 경우는, 컴공 출신도 아니고 SI계열사로 입사해서 그룹 전보 된 케이스라서 회사의 동기들과 일면식도 없기 때문에.. 그런 점이 종종 부럽기도 했다. 그래서 나름대로 자주 블로그들을 즐겨찾기 해 두고 트렌드를 파악하려 하지만, 100% 개인의 노력으로 급변하는 IT트렌드를 모두 파악하는것이 쉬운일이 아니라는 것을 깨달았다.(할 수야 있겠지만 시간이 정말 많이 든다.) 그래서 이 부분을 효율화/최적화 할 방법이 없을까 생각하다가 문득 취업준비할 때..
현재 재직중이 회사에서 검색 색인 파일을 추출하기 위해 몽고DB의 aggregationPipeline을 사용중이다. 커머스 중에서도 굉장히 복잡한 데이터 스키마를 가진 편이기에, 파이프라인이 복잡한것은 물론이고 lookup하는 컬렉션은 수십개가 되고, 그중 몇몇 컬렉션은 단일 컬렉션의 도큐먼트만 수십억건이 있다. 그렇게 AggregationPipeline을 사용하던 중 의문이 생겼는데, 상식적으로 RDS에서던 NoSQL에서던, 추출되는 결과 컬럼의 갯수를 줄여 꼭 필요한 컬럼만을 추출하는 것이 (SELECT * 을 사용하지 않고 SELECT절에 꼭 필요한 컬럼명만 지정) 성능이 좋다는 것은 튜닝의 기본중의 기본인데 이상하게 문제가 된 대형 Aggregation Query에서는 각 Stage에 $proje..
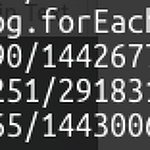
// 롱 쿼리 확인 db.currentOp({"secs_running":{"$gte":3}}).inprog.forEach( function(op){ printjson(op); } ) // 롱 쿼리 kill db.currentOp({"secs_running":{"$gte":3}}).inprog.forEach( function(op){ db.killOp(op.opid); } ) 종종 application을 강제종료했는데도 쿼리가 계속 실행중인 경우가 있다. 강제 종료 할때는 query들도 모두 종료되었는지 확인하는 습관을 갖는게 좋다
killIndexMaking = function(a) { currOp = db.currentOp({"op": "command", 'query.createIndexes':'collection_name'})['inprog'] print(currOp) // 만들고있는 인덱스가 맞는지 check print("Killing opId: " + currOp[0].opid); //db.killOp(currOp[0].opid); // 죽인다. }; killIndexMaking(1)
 [mongoDB] mongoDB 인덱스 생성 진행상태 확인하기
[mongoDB] mongoDB 인덱스 생성 진행상태 확인하기
mongoDB는 background로 index를 생성할수 있어서 아주 유용하게 사용하곤 한다. index 생성시 option으로 background:true를 지정하면 백그라운드로 컬렉션에서 진행중인 작업들에 영향을 주지 않고 인덱스 생성이 진행된다. db.collection_name.createIndex({index description}, {options}) ex) db.my_collection.createIndex({field1:1, field2:-1}, {background:true, partialFilterExpression : {field3:{$exists:true}}}) 하지만 진행상태를 콘솔로 찍어주진 않기때문에 진행상태 확인은 아래와 같이 해야한다. db.currentOp(true).i..
 [Infra] Apache-Tomcat 무중단 배포 구성기 - (2) 최종 적용 방식 및 warm-up
[Infra] Apache-Tomcat 무중단 배포 구성기 - (2) 최종 적용 방식 및 warm-up
세번째 시도 // Worker의 Status를 직접 제어하자 (성공) jk status (status worker) 또는 graceful restart jk status manager의 web view 화면. 이런게 웹 포트가 열려있다니 방화벽으로 막는다고 해도 꺼림칙하다.. js status manager worker의 상태를 관리하는 worker를 별도로 띄운다 해당 status worker에 GET 요청을 날려서 worker의 상태를 확인하거나 변경할수 있음 해당 페이지에 접근하게되면 서버들을 모두 disable 할 수 있기때문에 보안상 좋은 방법은 아니라고 생각함 apache graceful restart 서버에서 설정파일을 직접 변경, 아파치를 reload하는 방식 장점 : apache grac..
 [Infra] Apache-Tomcat 무중단 배포 구성기 (1) 구상 및 실패 사례
[Infra] Apache-Tomcat 무중단 배포 구성기 (1) 구상 및 실패 사례
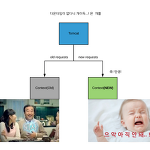
회사 위키로 공유했던 내용 옮겨적기 .. 어떤 방식으로 할 것인가 무중단 배포의 방식 Rolling Blue/Green Canary 일부 User(ex. 내부 테스터)만 새로운 버전으로 접근되도록 한 상태에서 모든 검증을 마친 뒤 전 사용자 대상으로 오픈한다 별도의 인프라를 구성하여 라우터에서 분기하거나, (모든 요청이 client에서 시작된다면) 내부 테스터의 hosts 파일을 수정하여 일부 사용자만 신규 버전에 접근하도록 할 수 있다 기존의 인프라 구성 물리 서버 한대에 아파치 httpd (web서버) 1대 + 톰캣 WAS 2대가 배포되어 있으며 2대 모두 트래픽을 받고 있음 어떤 방식을 적용할 것인가 (+ 기준) 운영중인 서비스들에 적용하는것이기 때문에 제 1 전제는 서비스의 퍼포먼스에 영향을 주지..
 [Infra] 빌드 배포 서버에서 user home 디렉토리 용량 가득 참
[Infra] 빌드 배포 서버에서 user home 디렉토리 용량 가득 참
어제 '혹시 빌드 배포 장비 용량이 꽉 찼나요..?' 라는 연락을 받았다. 해결 과정도 심플하고, 글로 정리할것도 많지 않아서 블로그 첫 글로 남겨보려 한다. 1. 우선 용량을 찍어보자 $df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 63G 0 63G 0% /dev tmpfs 63G 0 63G 0% /dev/shm tmpfs 63G 1.2M 63G 1% /run tmpfs 63G 0 63G 0% /sys/fs/cgroup /dev/nvme0n1p1 10G 5.6G 4.5G 56% / /dev/nvme2n1 50G 52M 47G 1% /app_log /dev/nvme1n1 9.8G 9.2G 3.7M 100% /usr_home /dev/nvme3n1 ..
사실 아주 예전에 네이버 블로그에서 기술 블로그를 만들어 본 적이 있다. 그땐 글 하나하나를 그림도 무식하게 직접 그리고 본문도 첨삭하면서 지나치게 정성들여 쓰던 탓에 게시글 10개도 채우지 못하고 그만뒀던 것 같다. 결정적으로 그렇게 시간을 들여 쓴 만큼 더 기억에 남는다던가, 더 깊이 이해하게 되는 느낌이 들지 않았었다. 그도 그럴것이 정보의 공유나 개발자로서의 일기, 내 고찰의 과정을 기록하는 도구가 아닌 그저 나도 멋진 블로그를 갖고싶다는 생각에 꽂혀 있었던 것 같다. 그렇게 '나는 개발블로그와 맞지 않는다.', '나는 블로그보다 내 노트에 정리하는게 편하고 효과적인 사람이다.' 라고 생각하며 취업을 하고 벌써 6년차 개발자가 되었다. 이제서야 생각한다. 그때 별 볼일 없다고 생각했던 그 고민과 ..